
][31 mai 2019] Pourquoi « Intelligence artificielle et machine learning COMMENT ça MARCHE » ?
Pour répondre à une invitation pour participer à la 21E UNIVERSITE DE PRINTEMPS DE L’AUDIT SOCIAL (à Genève) sur l’intelligence artificielle appliquée aux métiers de la gestion du capital humain !
Avec Alexis (mon associé), nous n’avons pas hésité ! Avant de savoir ce que l’on peut faire de ces techniques, il pourrait être utile de savoir comment ça marche, non ?
Une fois que vous aurez compris les concepts, vous comprendrez vite comment les professionnels s’en servent de manière pratique.
[mise à jour du 30 novembre 2020 : pour une version plus technique de l’Intelligence artificielle, du deep learning et du machine learning, cliquez sur ce lien]
Intelligence artificielle et machine learning COMMENT ça MARCHE ? du logiciel…

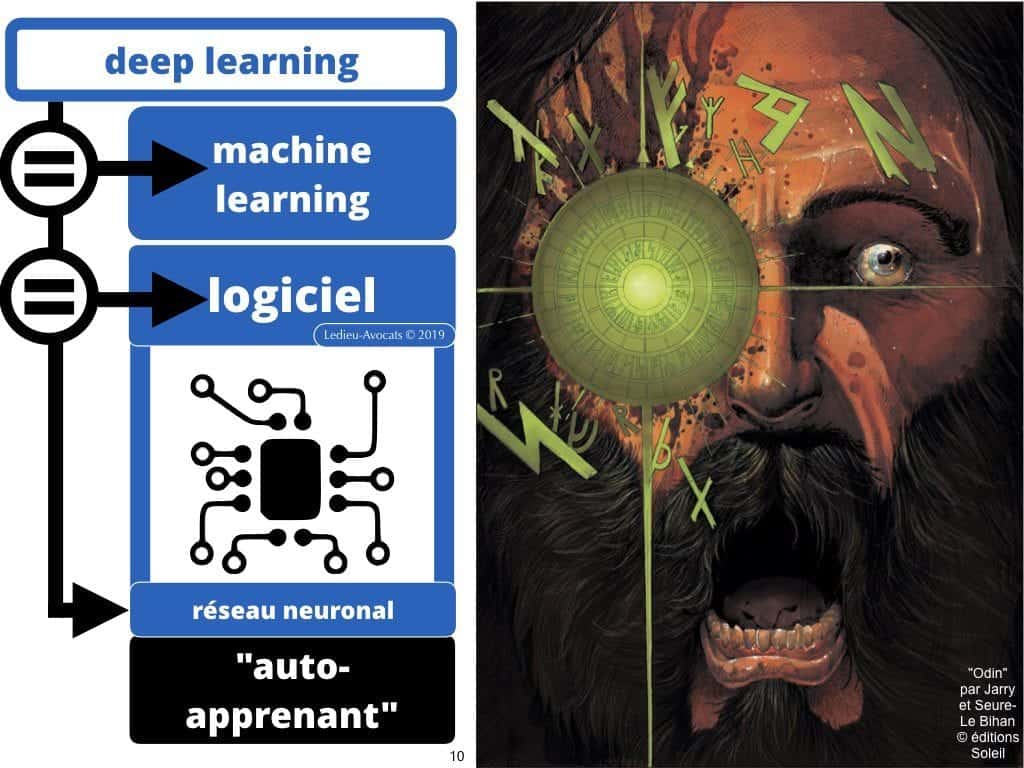
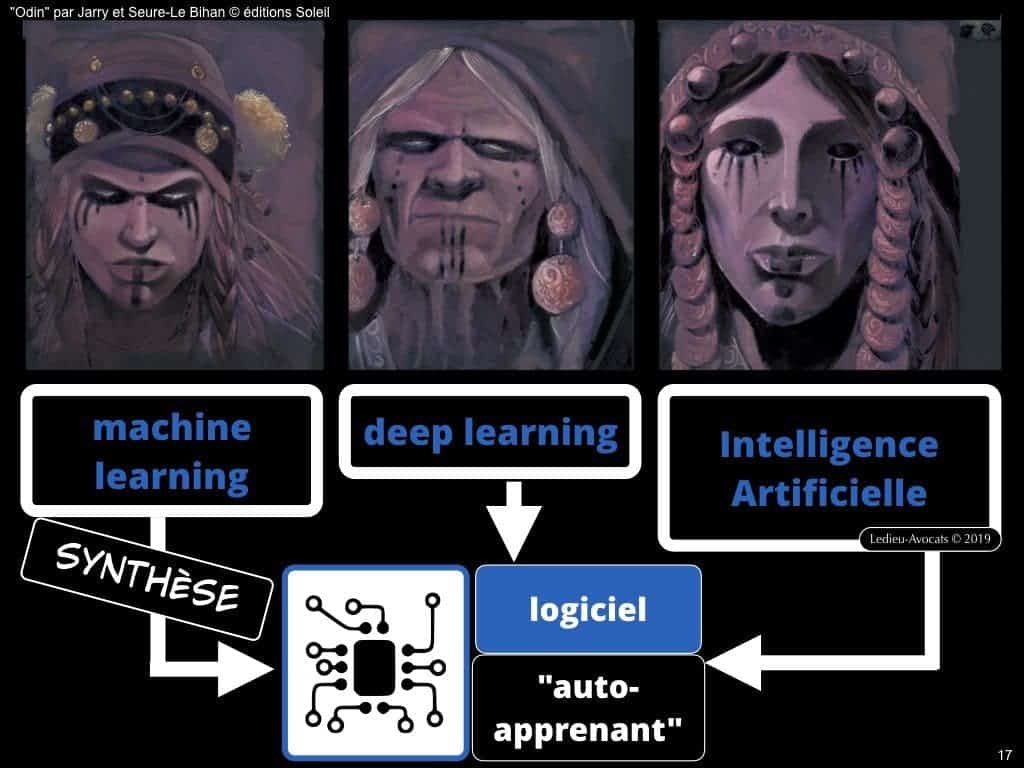
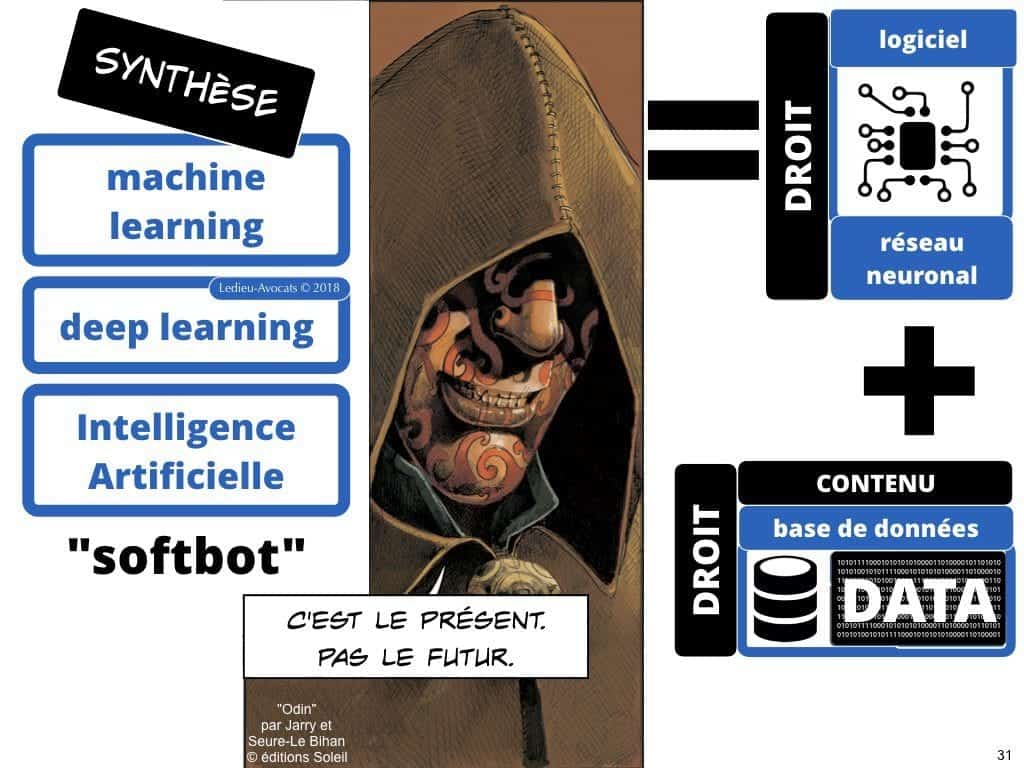
Pour une fois que ce ne sont pas nous, les juristes, qui compliquons les choses… Aujourd’hui, oubliez vos fantasmes de robots humanoïdes (associés)… L’intelligence artificielle, c’est de l’intelligence logicielle de nouvelle génération.
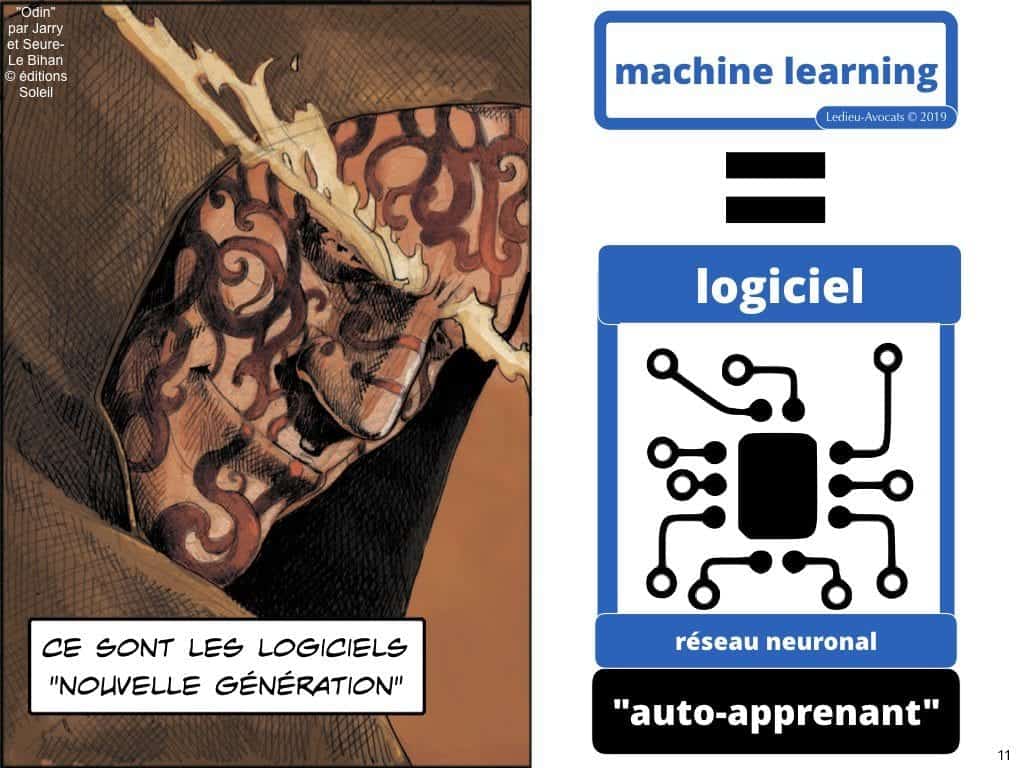
Le terme, moins sensationnel, mais plus exact pour évoquer cette nouvelle génération de « programme d’ordinateur » (c’est le terme légal dans l’UE avec la Directive 2009/24 du 23 avril 2009), c’est « machine learning ». Vous pouvez également utiliser les termes « deep learning » ou « apprentissage profond » ou « réseau neuronal »… Pour nous, les juristes, cela reste du logiciel.
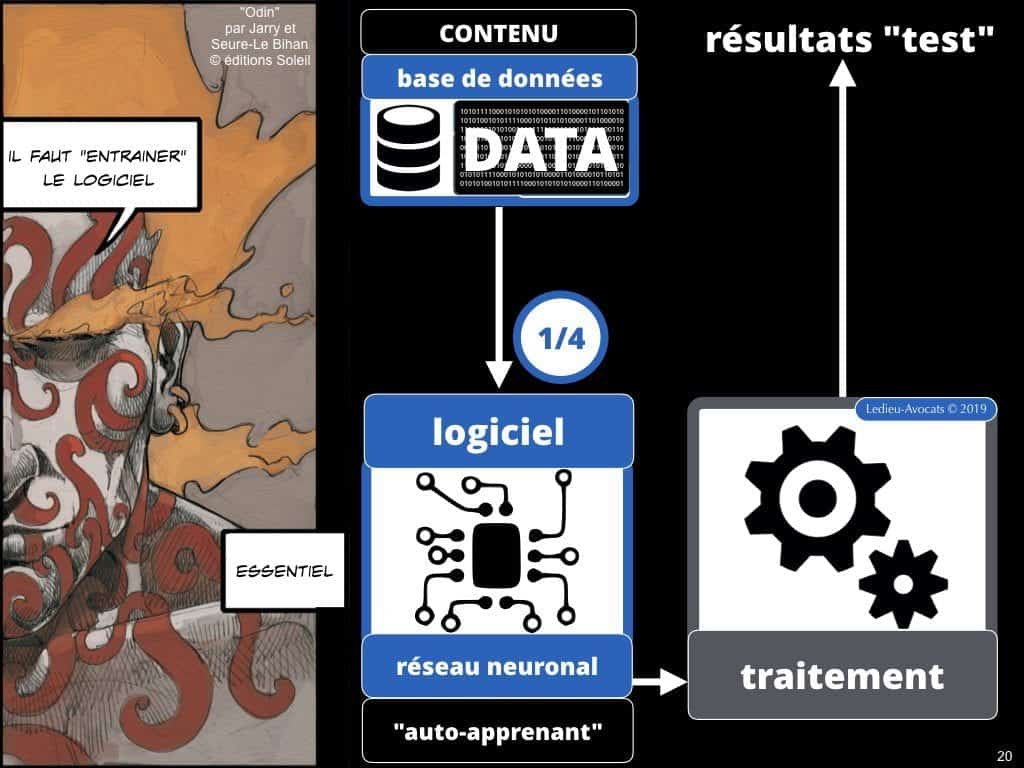
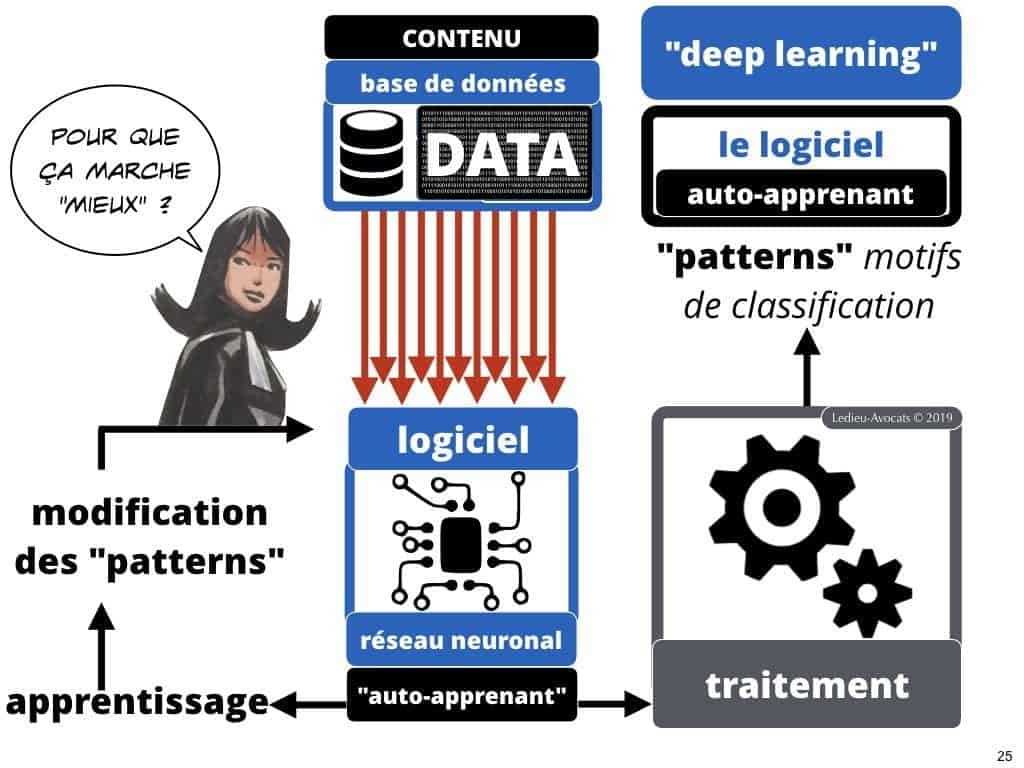
Intelligence artificielle et machine learning COMMENT ça MARCHE ? entrainer le logiciel à traiter des données
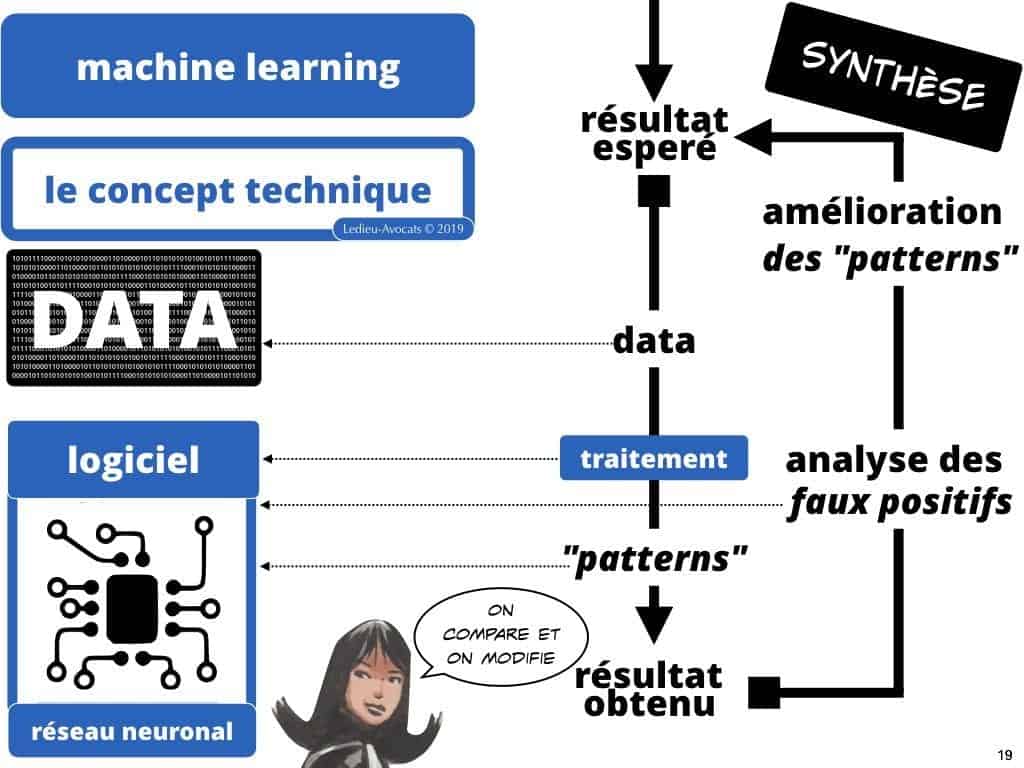
Le concept de machine learning ? Fixez un objectif en terme d’exactitude sur le résultat attendu du traitement d’un stock de données. Tant que le résultat du traitement de vos données ne vous satisfait pas, remettez vos données à traiter dans lie logiciel, jusqu’à ce que le résultat vous paraisse probant… ou utilisable…

Intelligence artificielle et machine learning COMMENT ça MARCHE ? il faut beaucoup entrainer le logiciel
Je suis comme vous, si l’on me dit que cette chose artificielle est « intelligence », je vais penser « intelligence adaptable »…. Aujourd’hui, heureusement, ce n’est vrai que dans une certaines mesure. Car pour que le logiciel « progresse », il lui faut d’abord beaucoup apprendre d’une part, et lui permettre de se corriger d’autre part.
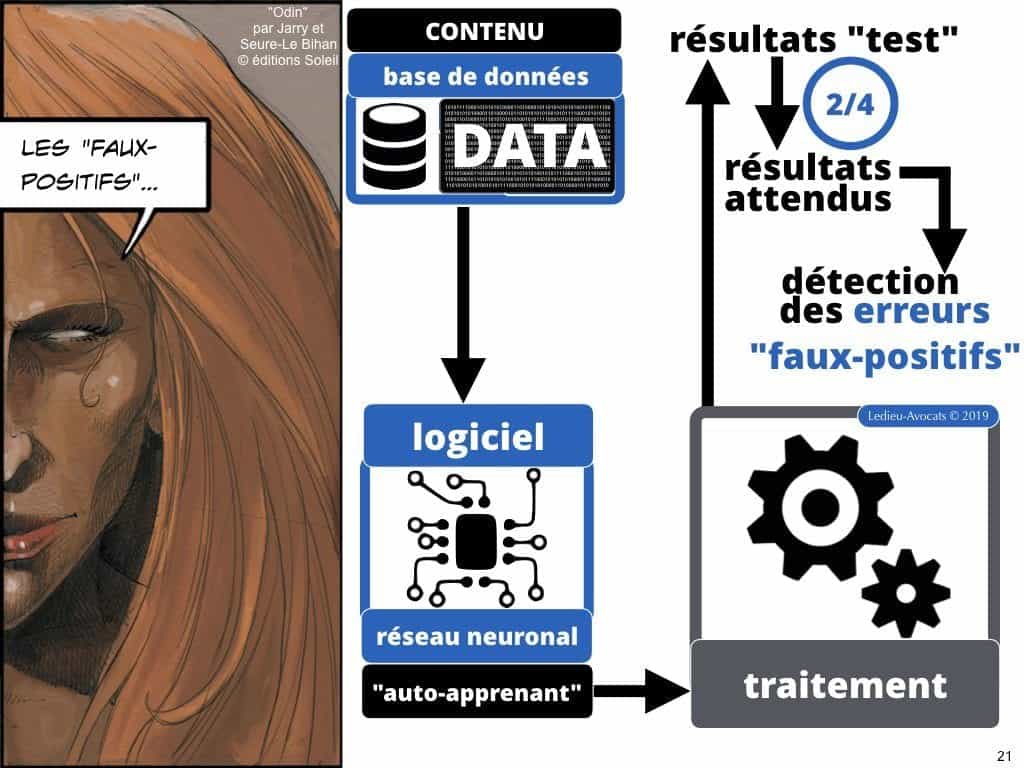
Intelligence artificielle et machine learning COMMENT ça MARCHE ? la notion de « faux positifs »
Si vous utilisez un logiciel de deep learning, c’est pour que votre outil puisse s’adapter à ce que vous lui demandez. Alors commencez par lui faire traiter des données test pour voir comment « sortent » les « résultats ». Ce qui « perturbe » la qualité du résultat, ce sont les « faux-positifs ».
Les résultats « mal classés » par le logiciel constituent des « faux positifs » : pour le logiciel, le classement de l’information traitée est correct, mais pas pour l’analyste humain… Dit par Wikipédia, ça donne ceci :
« Un faux positif est le résultat d’une prise de décision dans un choix à deux possibilités (positif et négatif), déclaré positif, là où il est en réalité négatif. Le résultat peut être issu d’un test d’hypothèse, d’un algorithme de classification automatique, ou tout simplement d’un choix arbitraire. »
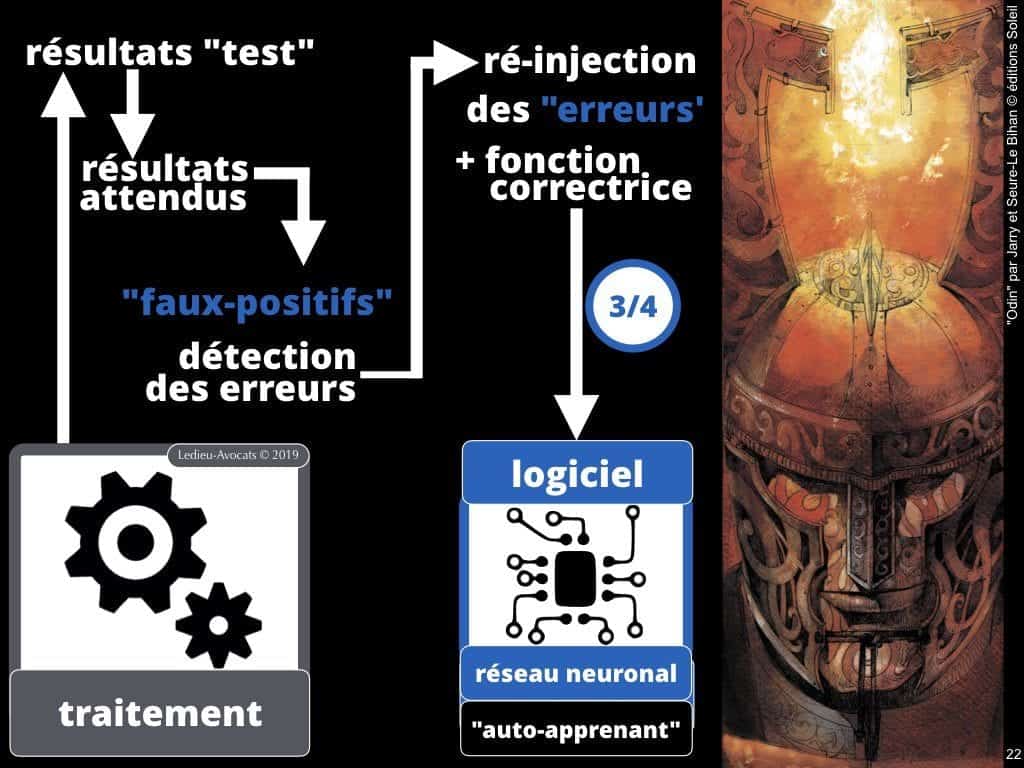
Intelligence artificielle et machine learning COMMENT ça MARCHE ? La correction des faux-positifs »

C’est en cela que ces logiciels sont… magiques. Une fois que l’humain a introduit une fonction correctrice destinée éliminer les faux-positifs, le logiciel « intègre » cette logique et la fait sienne… C’est en cela qu’il « auto-apprend ». De la correction par l’exemple, il peut en tirer une règle de fonctionnement futur.
Ces règles, ce sont les patterns de classification.

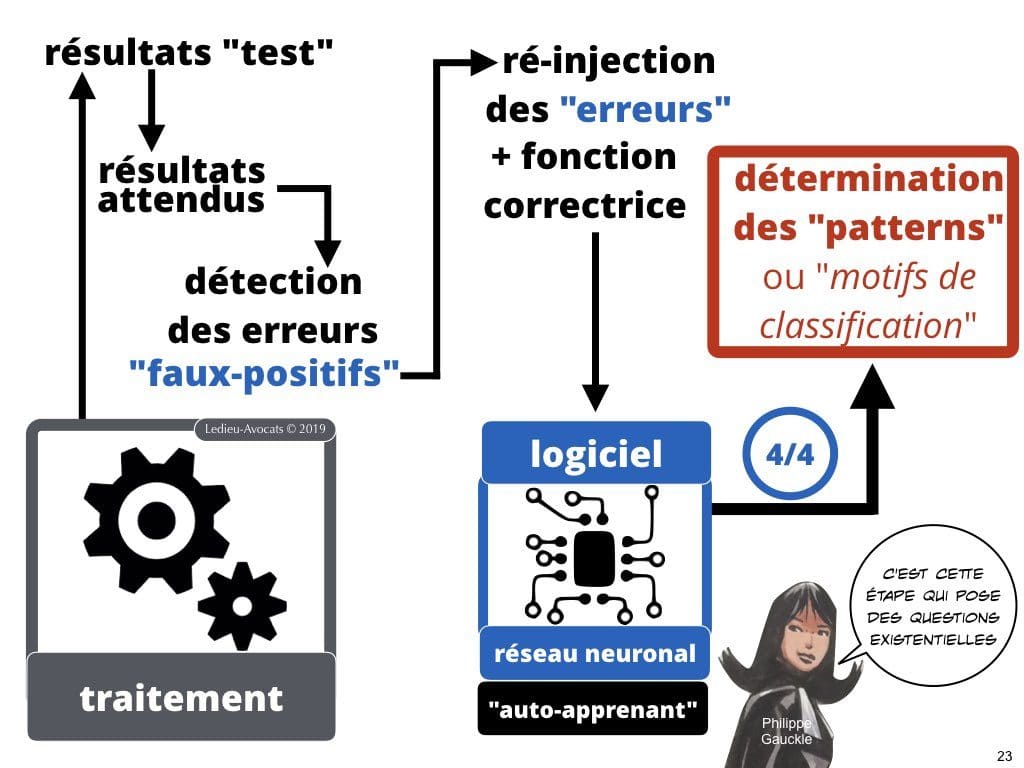
Intelligence artificielle et machine learning COMMENT ça MARCHE ? « patterns » ou « motifs de classification »
Voila l’intelligence attendue de ces logiciels de nouvelle génération : savoir adapter la classification de sortie, les « résultats » du traitement des données qui lui sont données.
Plus votre logiciel aura traité de données, mieux il les classera dans les bonnes cases… Evidemment, si vous injectez systématiquement « à la main » des fonctions de correction dans le logiciel pour que le résultat de ses analyses soit plus pertinent, vous ne faites pas du deep learning (mais de la modification de code source).
Si l’on parle « d’intelligence » de la part du logiciel, c’est grâce à sa « capacité » à apprendre seul à partir de la correction des erreurs et à affiner seul les patterns à partir de ceux qui lui ont été imposés par l’homme.
Pour le dire autrement, à partir d’un certain stade d’apprentissage, le logiciel fait évoluer seul sa capacité à classer des informations, sans que l’homme puisse expliquer « comment » le logiciel est parvenu à ce résultat. Voila le problème « éthique » posé par l’IA aujourd’hui.
Nous, les humains, en demandons toujours plus à la machine qu’à nous mêmes : nous voudrions tout savoir des patterns retenues final, même si nous sommes personnellement incapables de justifier (de manière rationnelle) une grande partie de nos choix !!!
Intelligence artificielle et machine learning COMMENT ça MARCHE ? la chasse aux idées reçues
Comme je rédige les contrats « business » sur des « softs » qui « embarquent » de » l’IA » (ça fait beaucoup de guillemets, non ?), il a bien fallu que je sois en mesure de répondre aux Frequently Asked Questions…
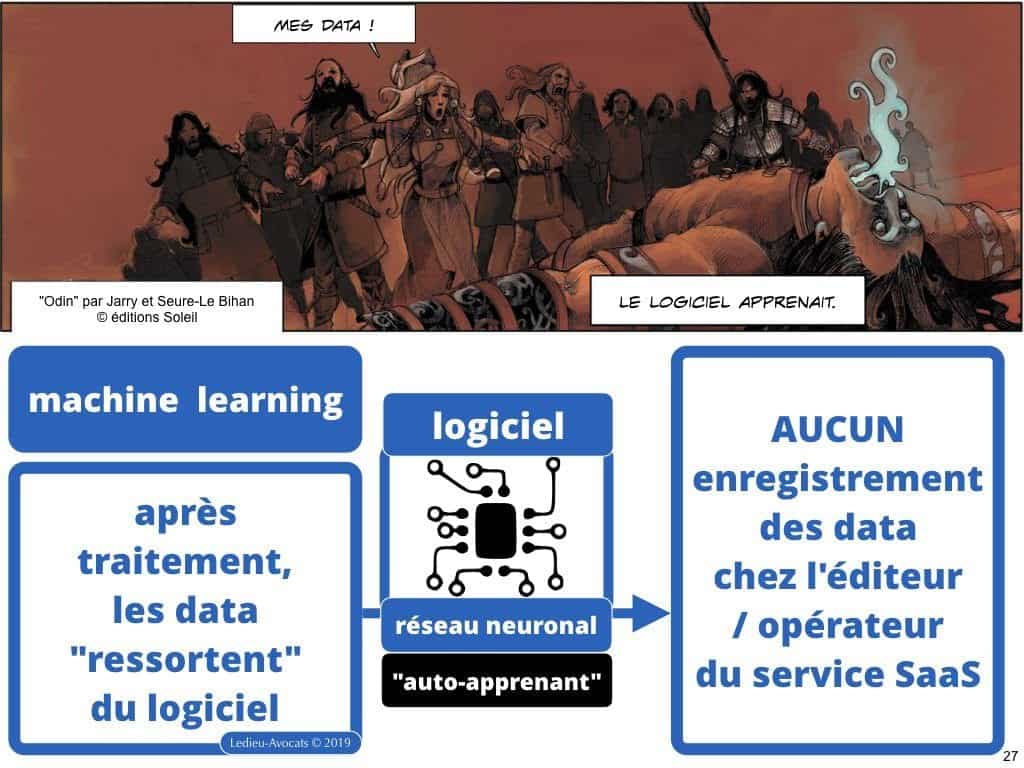
Non, une fois les data traitées par le logiciel, un process de machine learning ne permet pas en soi de constituer ou de répliquer de bases de données. Rassurez-vous, chers clients utilisateurs d’un logiciel embarquant une capacité à faire du deep learning, vous resterez « RGPD/GDPR » compliant… ATTENTION toutefois : certains prestataires de traitement de données aiment bien « rejouer » les data que vous leur avez confiées. Ceux-là risquent de sérieux problèmes juridiques : atteinte au droit du producteur de la base de données copiée, etc.

Intelligence artificielle et machine learning COMMENT ça MARCHE ? surtout QUI est « propriétaire » du résultat du traitement des données ?
Nous gagnerions en efficacité sur le sujet en nous rafraichissant la mémoire avec quelques concepts du droit des bases de données.

J’ai beau adorer la Directive 96/9 du 11 mars 1996, je dois le reconnaitre, aucune de ses dispositions ne permet de trancher le sort des data « sortie » du logiciel… Il vaudrait mieux être prudent et prévoir une petite clause contractuelle sur ce point… ça évitera des fâcheries inutiles…

Intelligence artificielle et machine learning COMMENT ça MARCHE juridiquement ? synthèse rapide

Intelligence artificielle et machine learning COMMENT ça MARCHE ? la présentation en BD tout entière dans le slider ci-dessous !

































































![cybersécurité 7 péchés capitaux [quelques réflexions pour convaincre nos décideurs de l'importance du problème] © Ledieu-Avocats 2025](https://technique-et-droit-du-numerique.fr/wp-content/uploads/2014/06/651-cybersecurite-7-peches-capitaux-quelques-reflexions-pour-convaincre-nos-decideurs-de-limportance-du-probleme-©-Ledieu-Avocats-29-06-2025.002-768x432.jpeg)

