
Lorsque des experts-comptables s’interrogent sur ce qu’est « l’intelligence artificielle », je dis oui tout de suite et je dégaine mes BD ! A l’invitation des Universités EURUS, en distanciel ce 13 octobre 2020 pour cause de Covid-19, vous trouverez l’ensemble des explications techniques et juridiques qui permettent de comprendre ce qu’est vraiment l’I.A., le machine learning et le deep learning.
Pour commencer du bon pied, voici le plan de cette présentation :

intelligence artificielle ? machine learning ? deep learning ? l'intro dans les slides ci-dessous !











intelligence artificielle : du fantasme au cinéma à la réalité en 2020
Le cinéma a beaucoup produit autours du thème de l’intelligence artificielle : « Planète Interdite » (1957), « Terminator‘ depuis 1984, etc.
Pourtant, c’est bien le film de Kubrick « 2001 l’odyssée de l’espace » (1968) qui rend le mieux compte de ce qu’est aujourd’hui en 2020 l’intelligence artificielle.
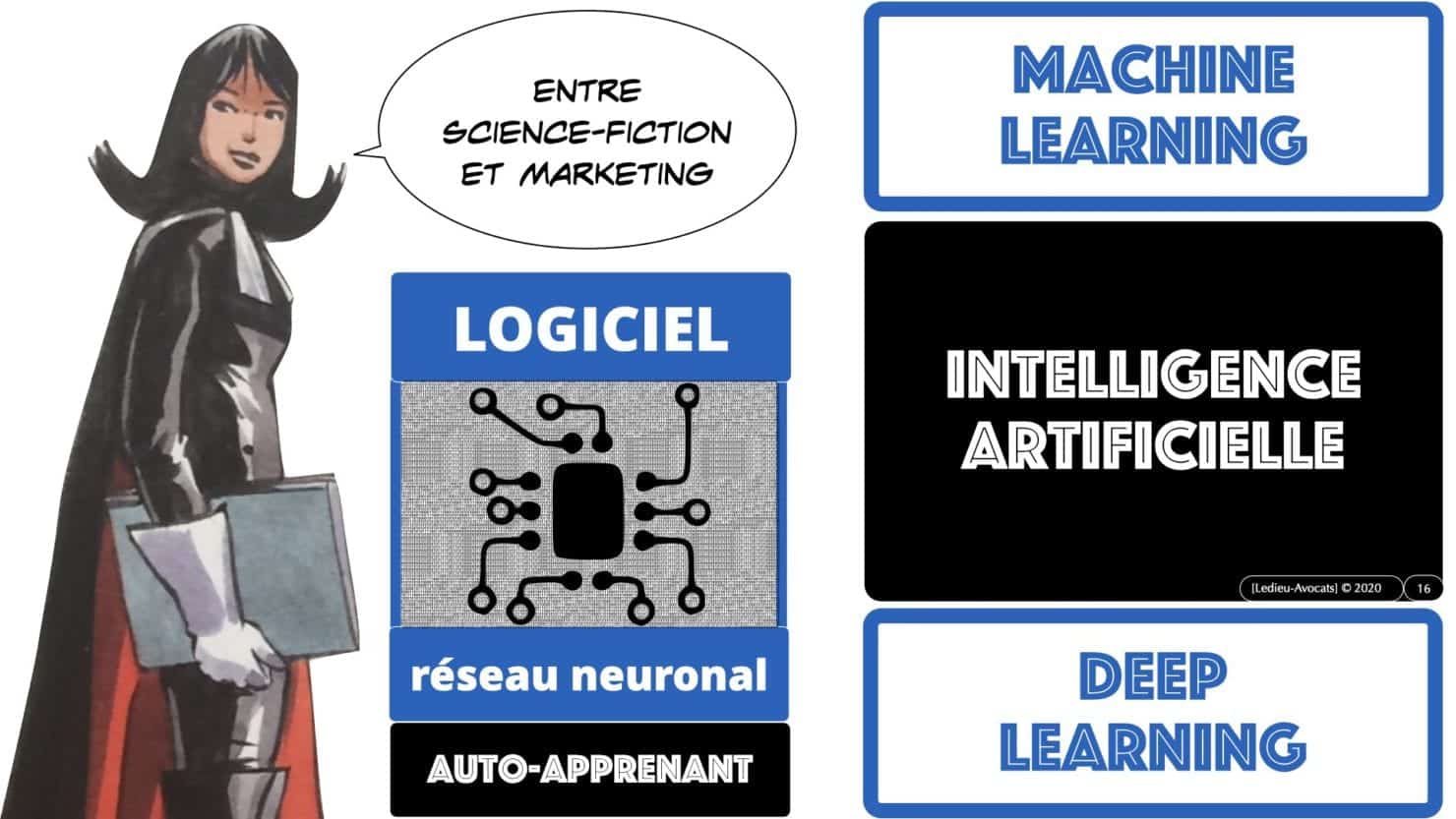
La « Mission Villani » en 2018 pose d’ailleurs une définition simple de ce qu’est une intelligence artificielle : un « logiciel » qui fait ce que des humains peuvent faire… mais mieux et plus vite (sinon, quel intérêt de confier cette tache à une machine ?).
Loin du fantasme du robot humanoïde, l’intelligence artificielle est donc aujourd’hui un traitement logiciel de données.
Nous n’insisterons pas aujourd’hui sur le droit du logiciel…
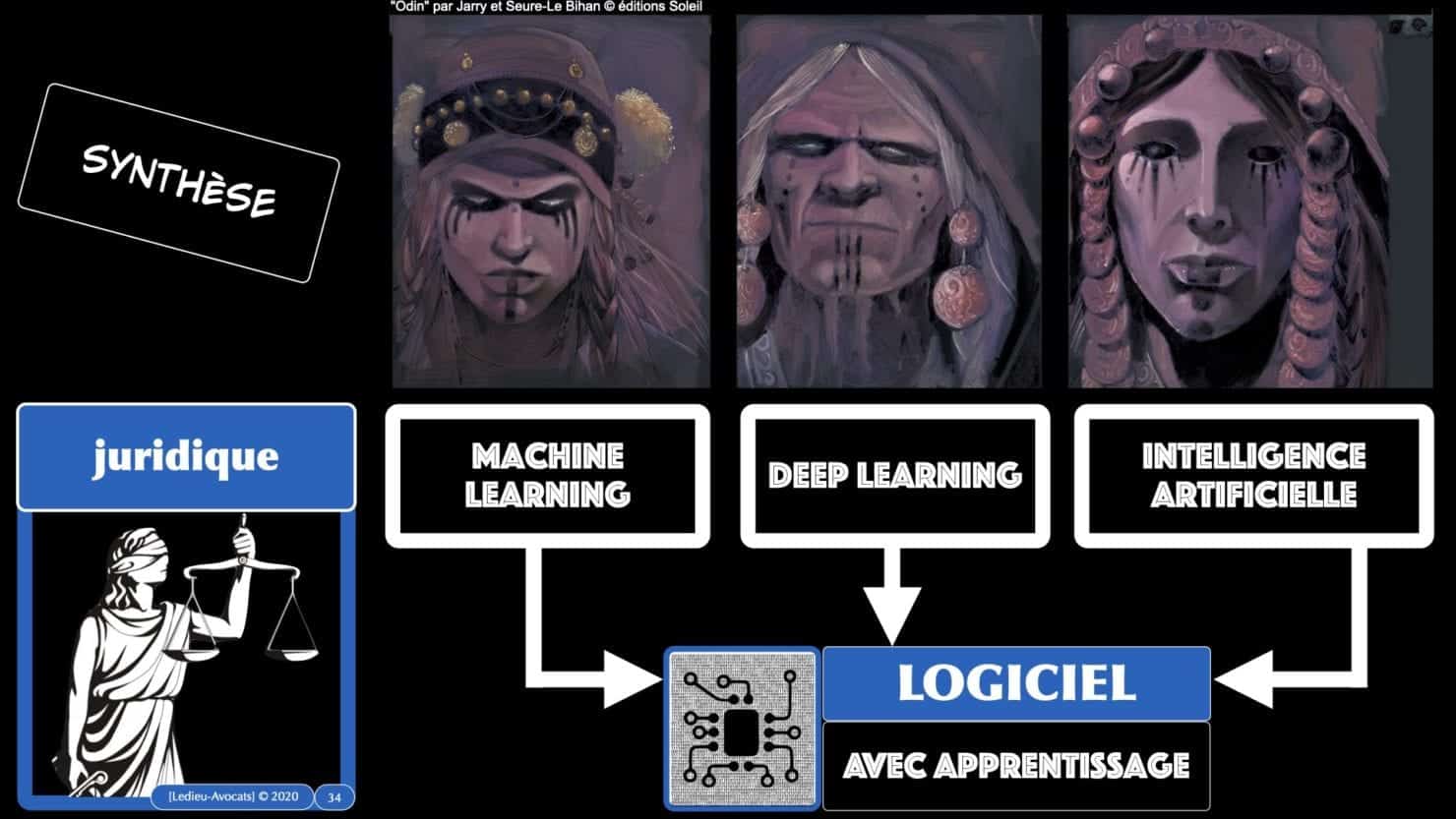
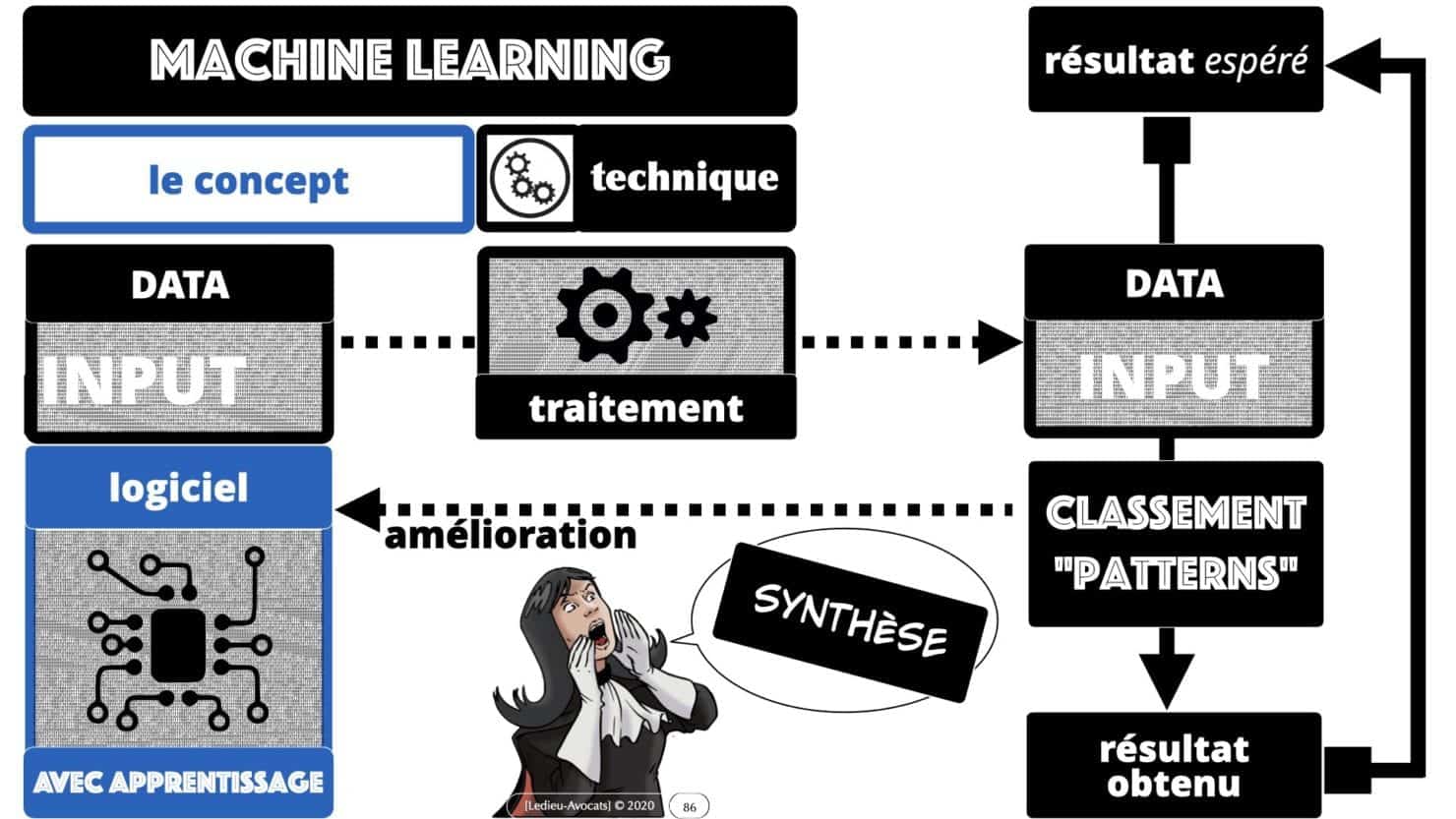
En synthèse ? intelligence artificielle = machine learning = deep learning = LOGICIEL !!!
Les slides de cette première partie sont dans le carrousel d’images ci-dessous.











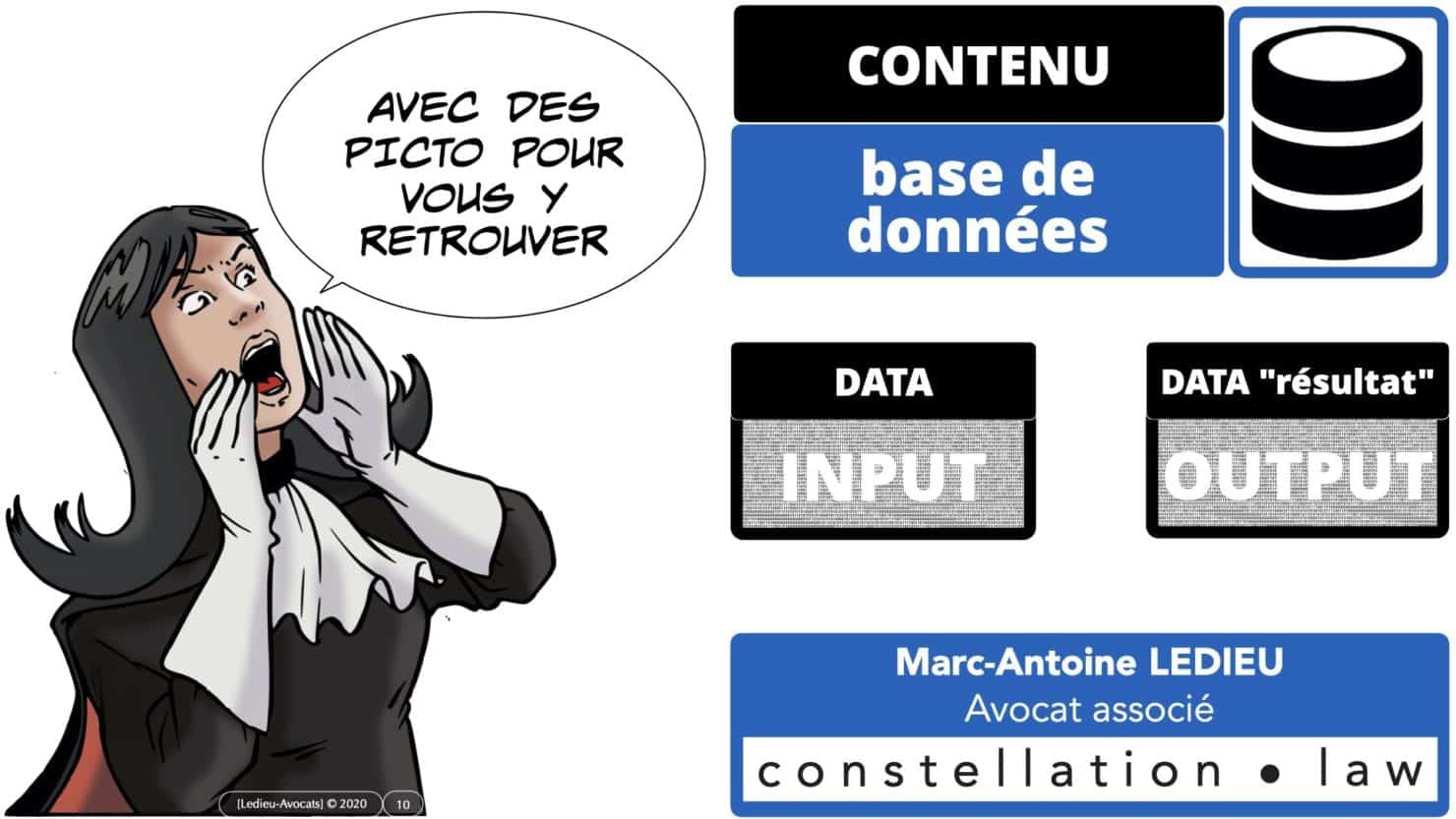
données INPUT ? données "résultat" OUTPUT ?
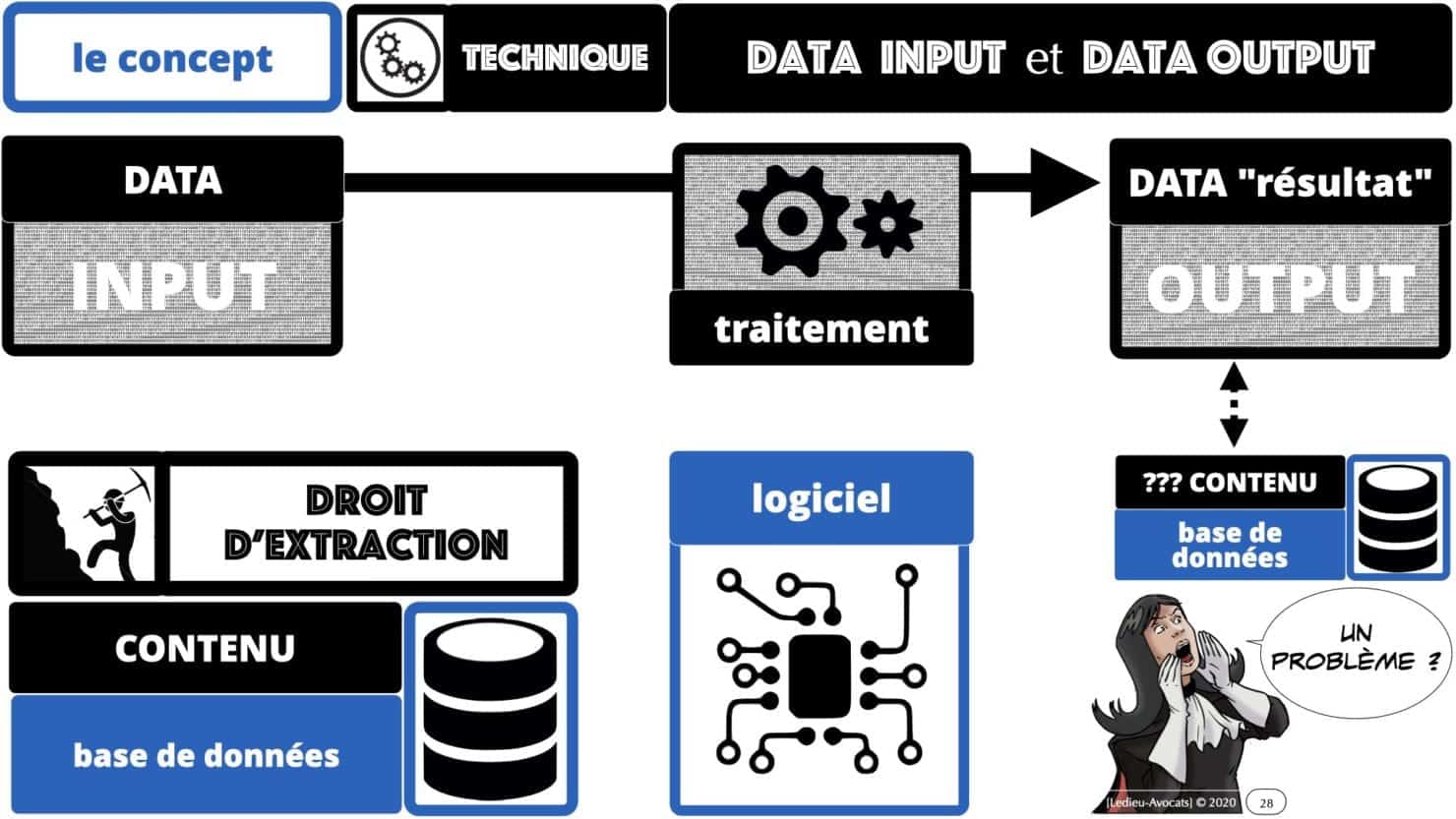
Pour comprendre techniquement et juridiquement « comment ça marche », penchons nous rapidement sur les notions de « données INPUT » et de « données OUTPUT ».
Les données INPUT, ce sont les données, le CONTENU d’une base de données, qu’il faut faire traiter par un logiciel.
Les données OUTPUT, ce sont les données résultant du traitement des données INPUT par ce logiciel, les données « résultat ».
Ce point est important dans la mesure où les contrats de service de traitement de données portent aujourd’hui mention des unes et des autres autres.
Sauf que pour l’intelligence artificielle, ça ne marche pas comme ça… Nous allons y venir…
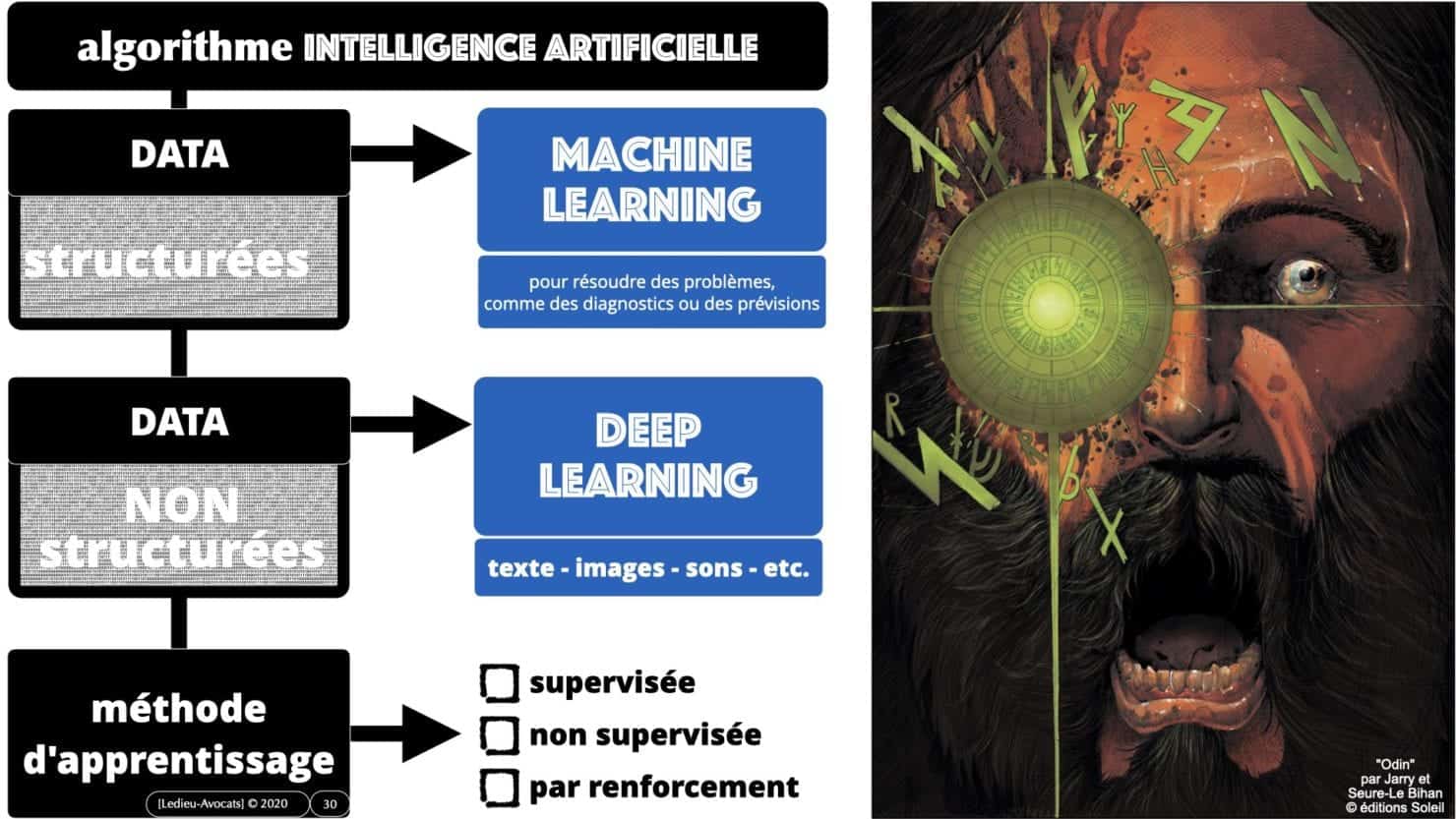
C’est dans ce chapitre que nous allons aborder (rapidement) la différence entre « machine learning » (I.A. sur des données « structurées ») et « deep learning » (I.A. sur des données « non structurées »).
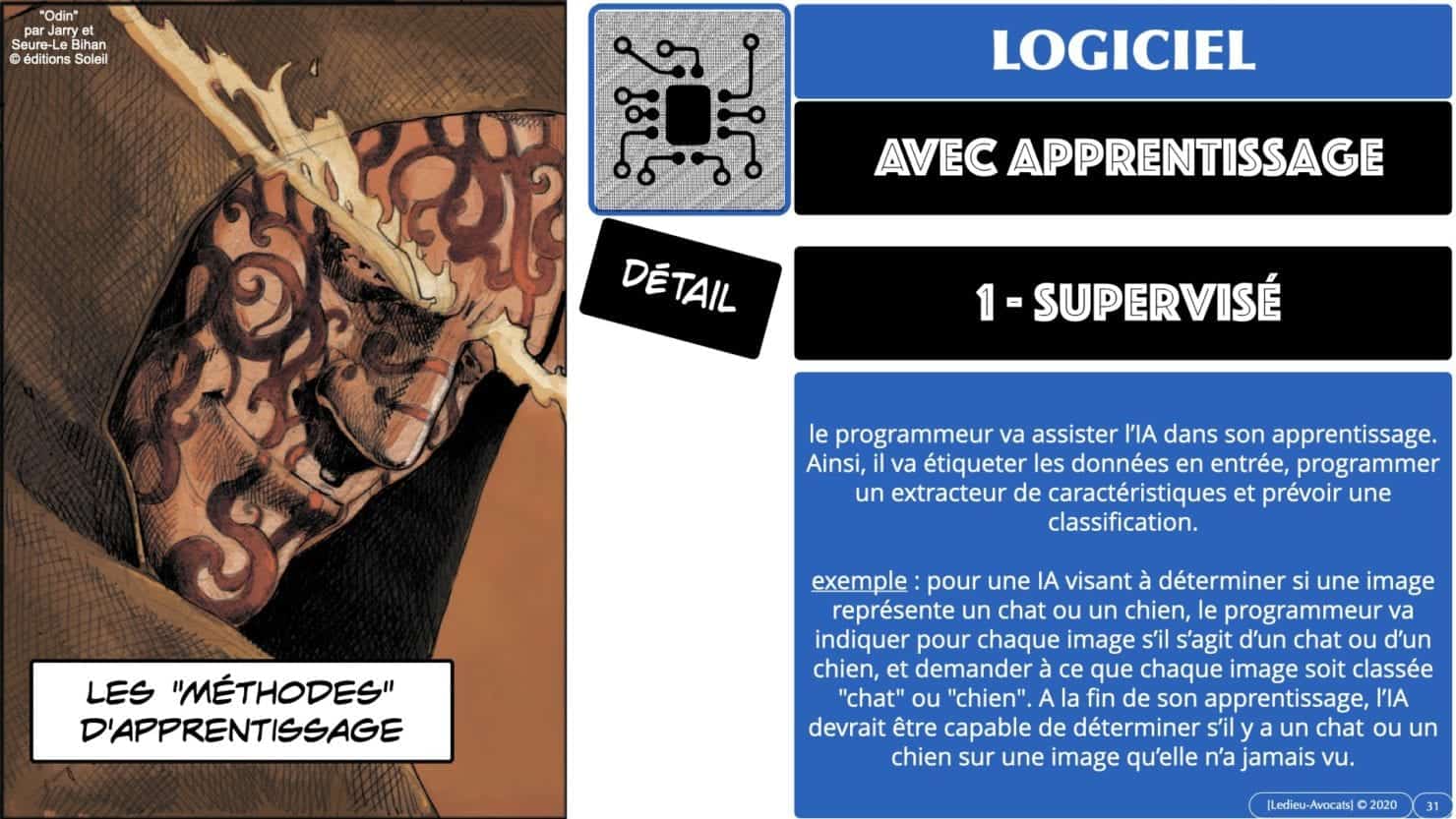
Nous jetterons également un coup d’oeil sur les méthodes d’apprentissage des logiciels / algorithmes d’intelligence artificielle :
– apprentissage « supervisé » (le logiciel travaille à partir de données « étiquetées » par son éditeur/utilisateur)
– apprentissage « non supervisé » : le logiciel travaille tout seul pour identifier les données provenant de textes / images / sons / etc. ça prend plus de temps car ce procédé demande beaucoup de données pour un résultat performant…
– apprentissage « par renforcement » : ce type d’apprentissage est utilisé pour les logiciels d’intelligence artificielle des voitures autonomes, qu’il faut entrainer jusqu’à ce qu’ils sachent piloter une voiture sans provoquer d’accident.
Pour plus de détail, référez vous aux images du caroussel ci-dessous.





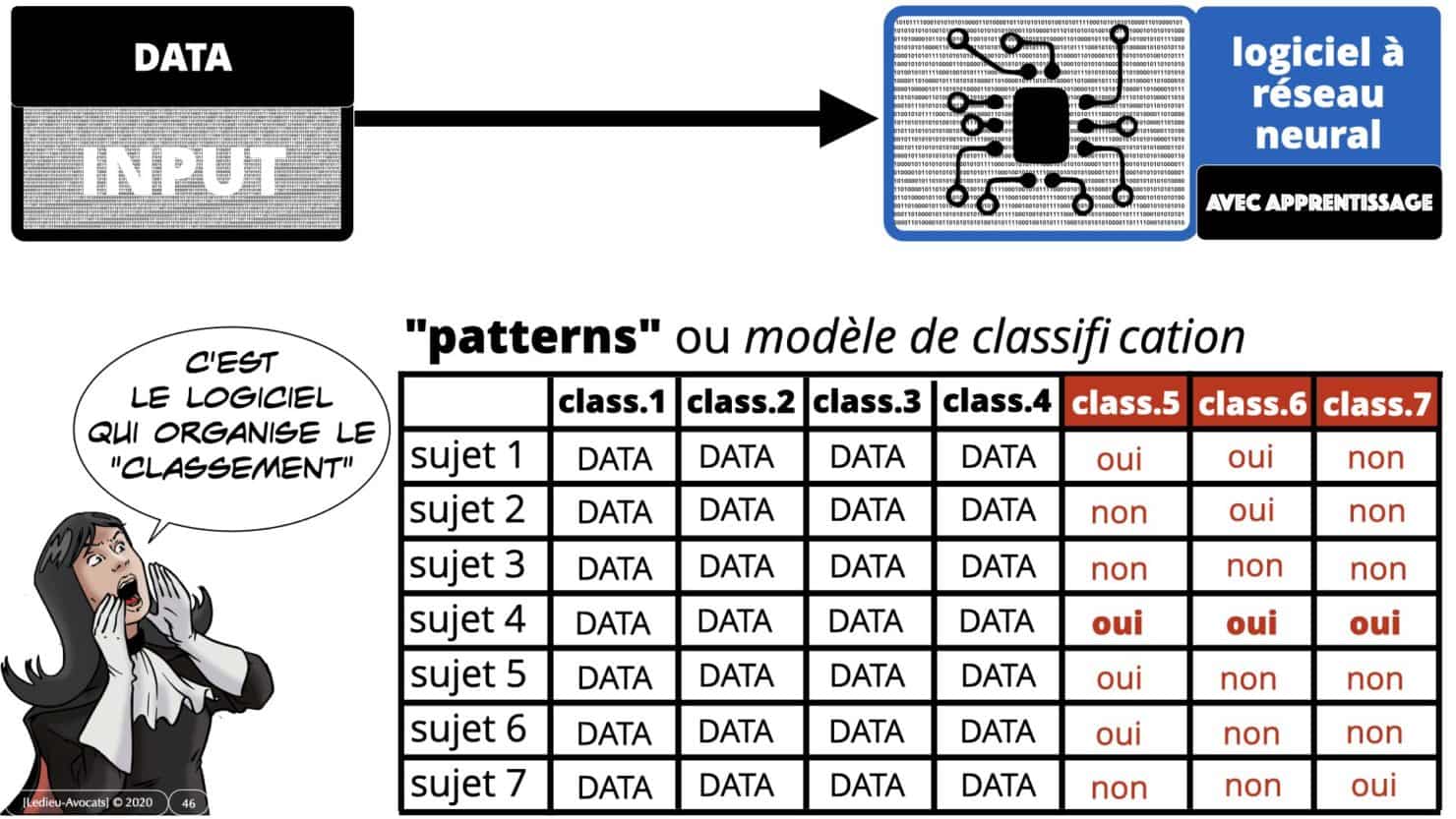
les "patterns" ou "modèles de classification"
C’est ici que l’on peut comprendre la différence entre « traitement de données avec data OUTPUT » et « traitement de données avec apprentissage ».
Les logiciels d’I.A. ne produisent aucune donnée OUTPUT : ils permettent en revanche de « classer » / « trier » / « segmenter » des données selon une logique et un détail qui n’ont pas été choisi par le concepteur du logiciel.
Pour rendre la chose plus parlante, regardez la slide ci-dessous : les concepteurs de l’I.A. ont voulu un modèle de classification des données avec les colonnes 1 à 4. Le logiciel, après apprentissage, va proposer d’autres colonnes de classification. Ce seront les colonnes 5 à 7.
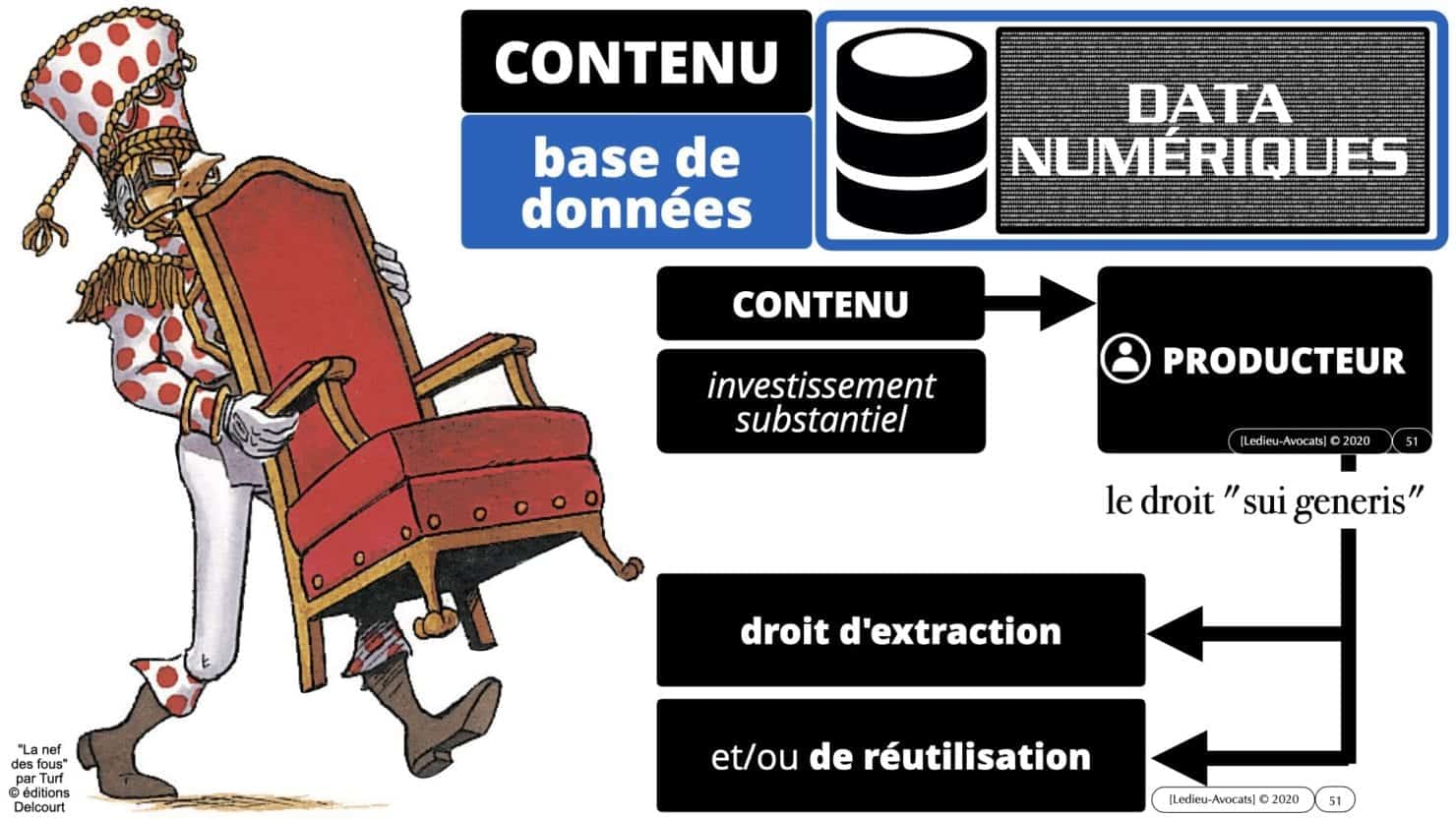
le droit du CONTENU des bases de données
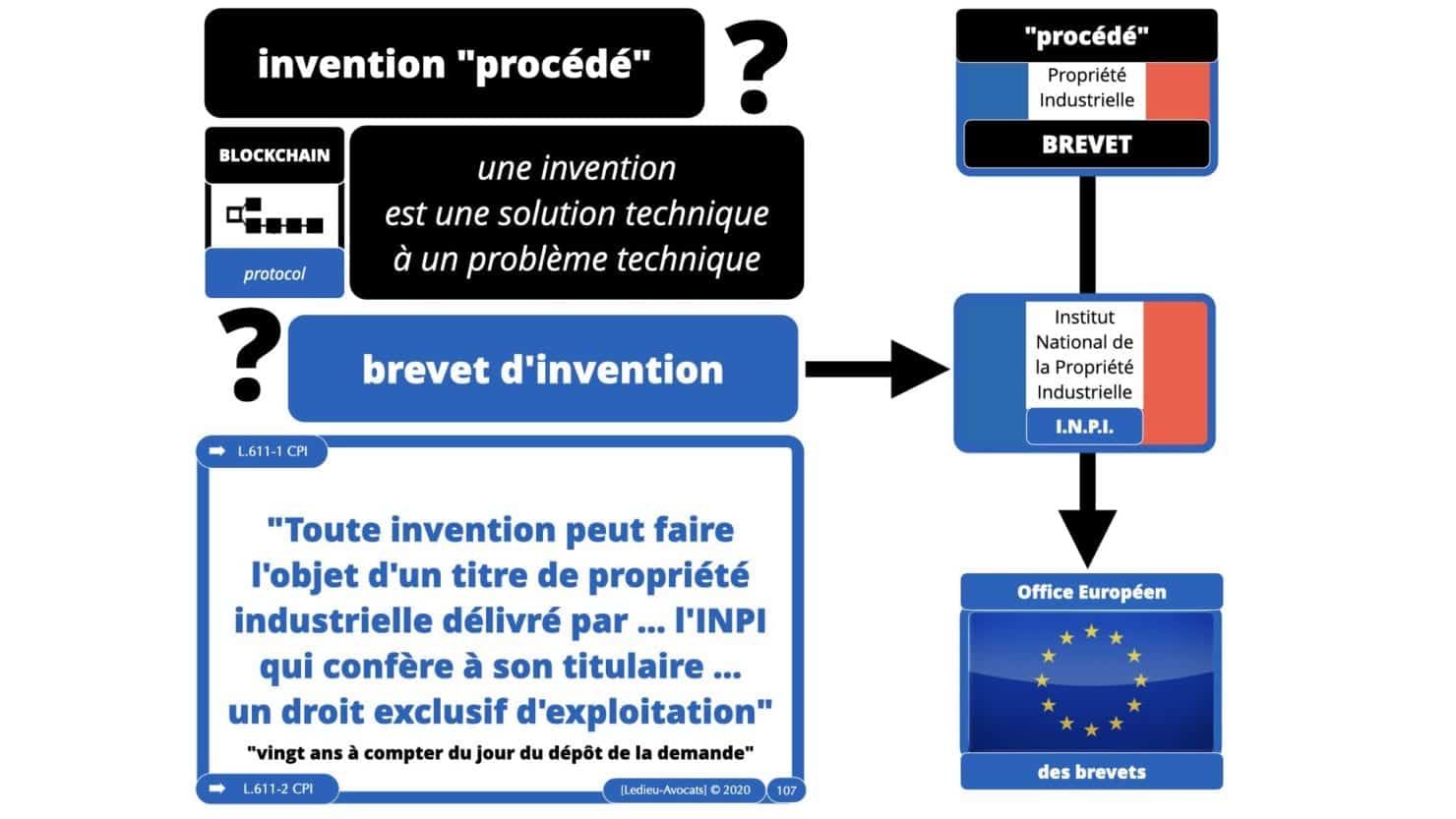
Pour comprendre les problèmes techniques et juridiques du machine learning et du deep learning, il faut maitriser les concepts de base du droit des bases de données (Directive 96/6/CE du 11 mars 1996) :
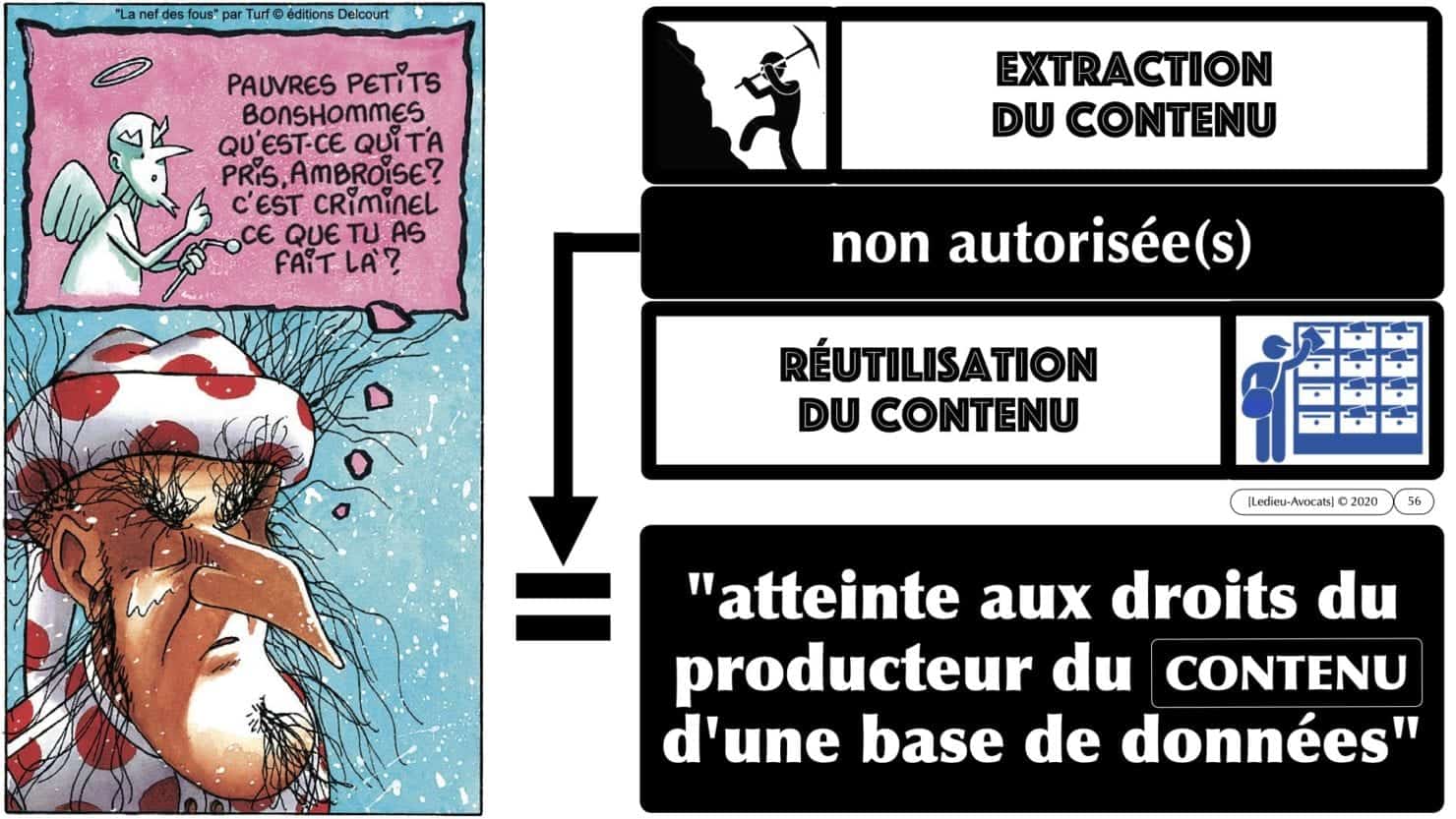
– le « producteur » du CONTENU d’une base de données doit prouver l’existence d’un « investissement substantiel » pour collecter et organiser les précieuses data.
– le producteur des data dispose d’un monopole légal sur l’exploitation de ses données, qui lui permet d’en interdire toute extraction et/ou toute réutilisation.
Le rappel (sommaire) de cette législation figure dans les slides ci-dessous.
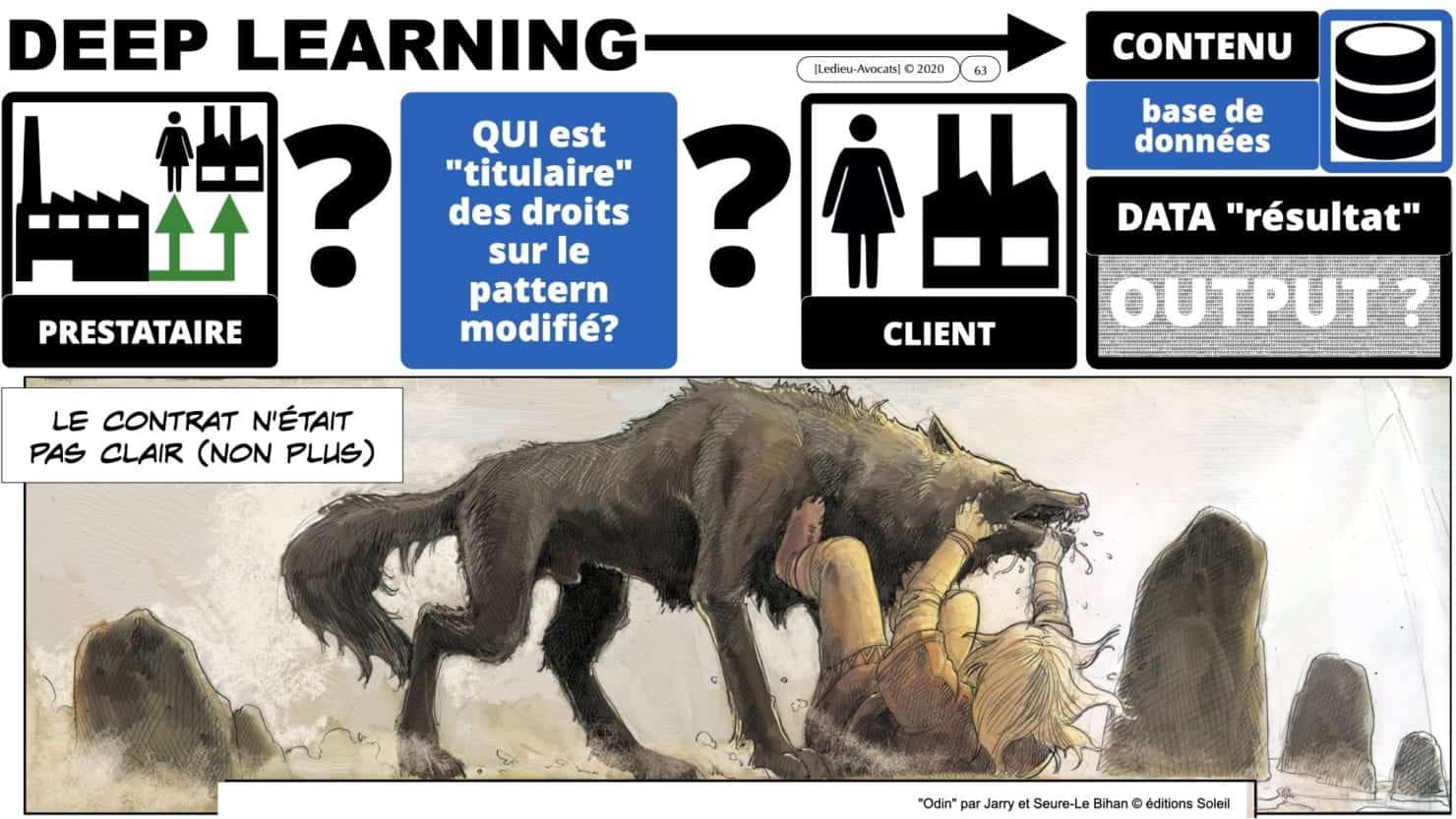
Nous en profiterons pour – justement – évoquer le problème que pose la titularité des droits sur les data OUTPUT et sur les « patterns » (modèles de classification) du logiciel avec apprentissage.
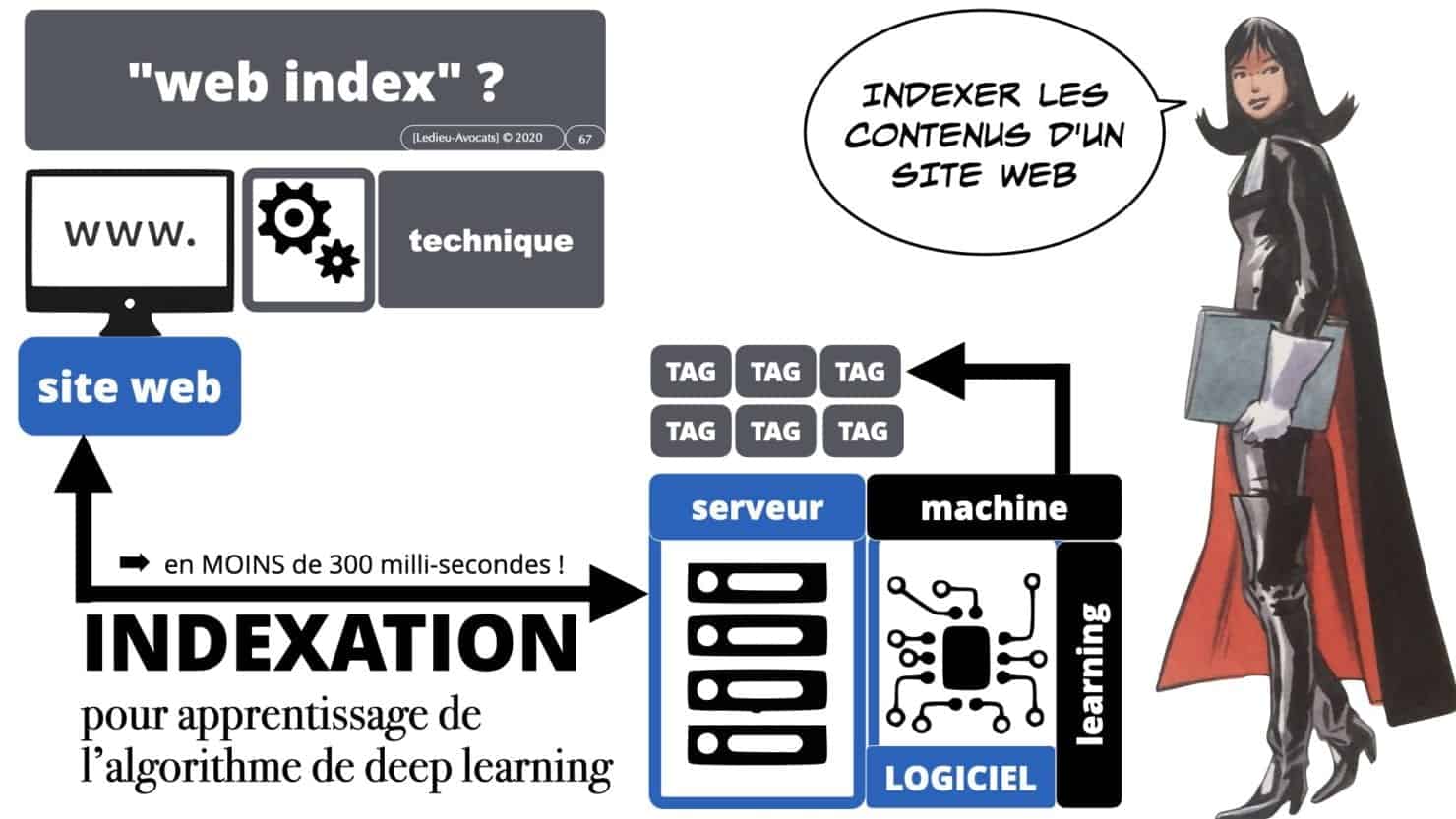
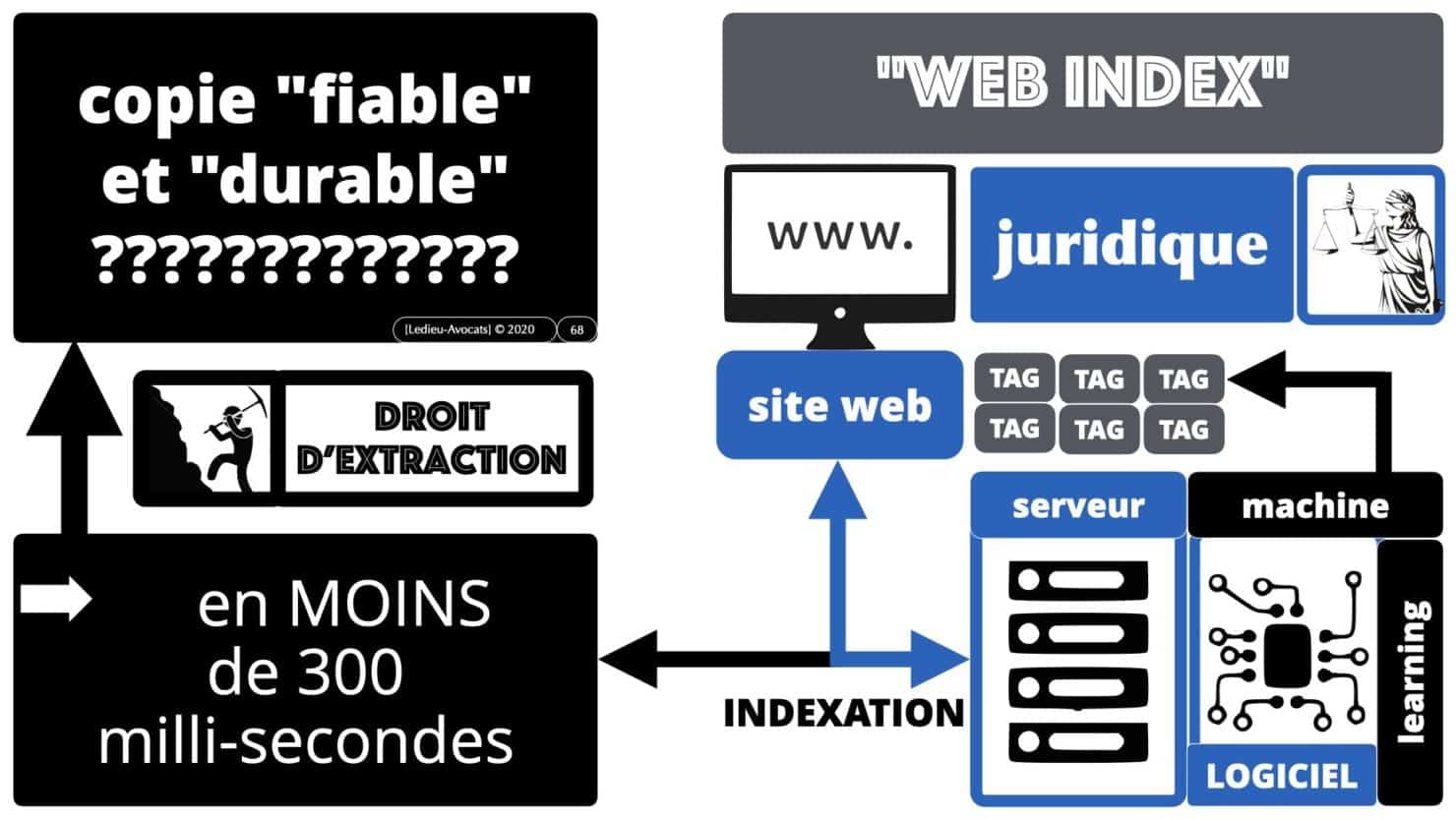
C’est à ce stade que nous évoquerons les problèmes liés au « web scrapping » et au « web index ».


















Intelligence artificielle, éthique et responsabilité
Le problème actuel des logiciels d’intelligence artificielle ? L’humain n’est pas en mesure d’expliquer « comment » le logiciel détermine ses « patterns »…
L’Union Européenne avait promis de s’intéresser au problème.
Vous pourrez lire avec intérêt le « livre blanc » de la Commission de Bruxelles du 19 février 2020.
Le 1er octobre 2020, cette même Commission annonce une prochaine législation européenne sur les problématiques de responsabilité et de droit d’auteur liées à l’intelligence artificielle.
Les slides ci-dessous vont donneront quelques détails supplémentaires.








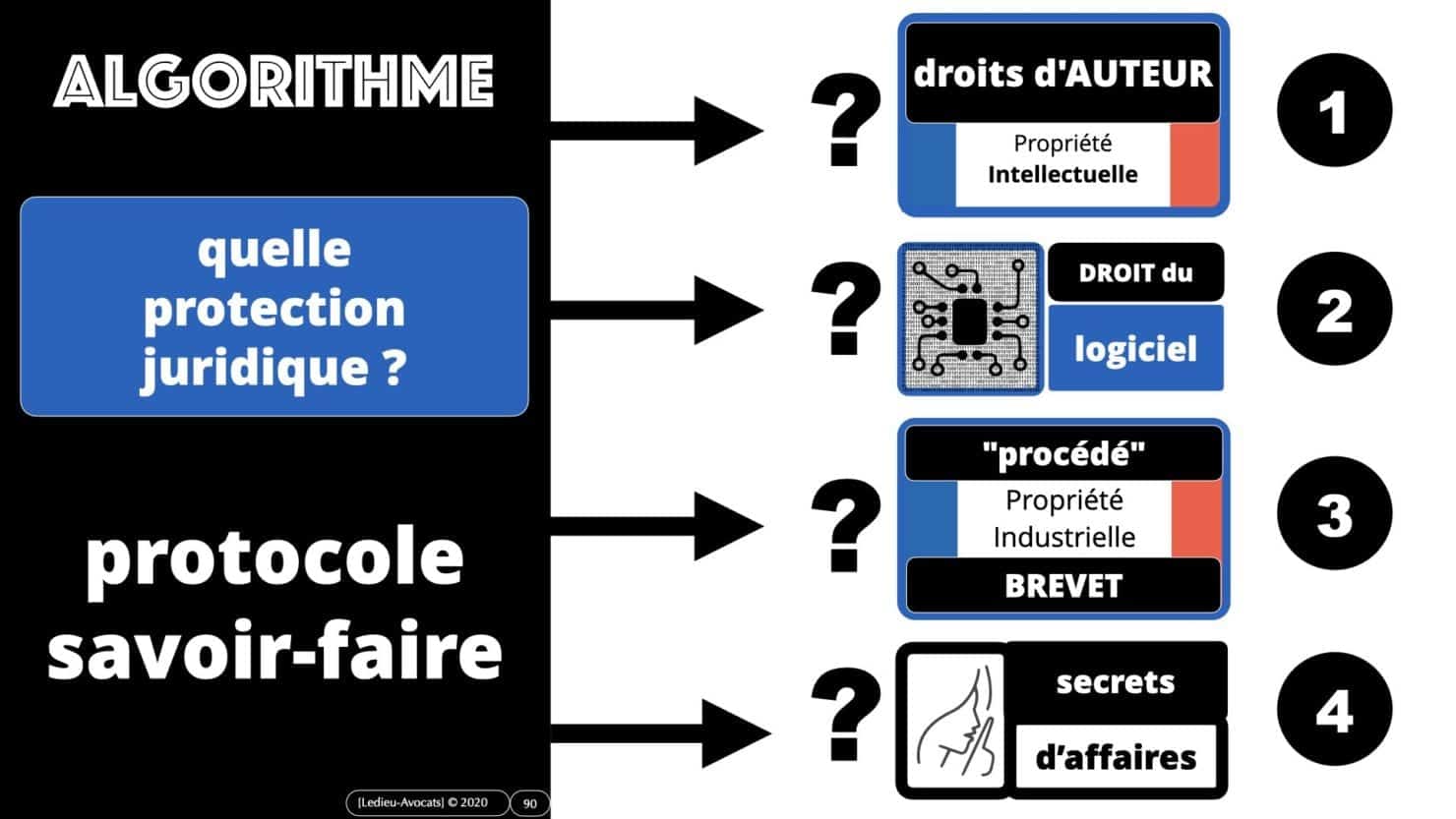
Algorithme ? algorithme d'intelligence artificielle ? quelle protection juridique pour les algorithmes ?
Je parle beaucoup de « logiciel » d’intelligence artificielle, les professionnels (journalistes en tête) évoquent plus volontiers les « algorithmes » de machine / deep learning. C’est à la mode…
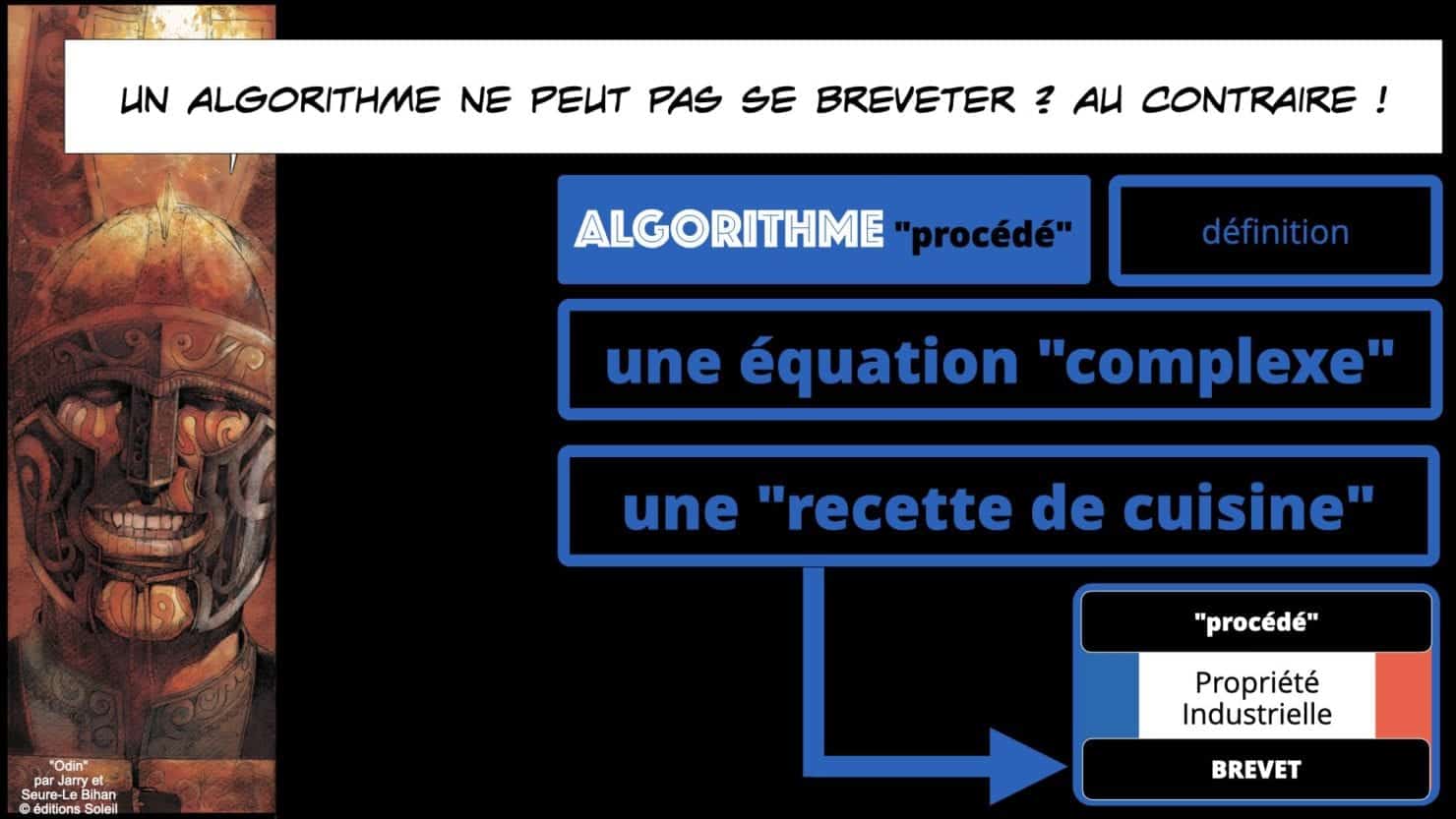
Voyons donc ce qu’est un « algorithme », et faisons simple : c’est une « recette de cuisine »…
Et, tant qu’on y est, voyons rapidement pour terminer « comment » protéger juridiquement un algorithme en envisageant les modalités principales de protection :
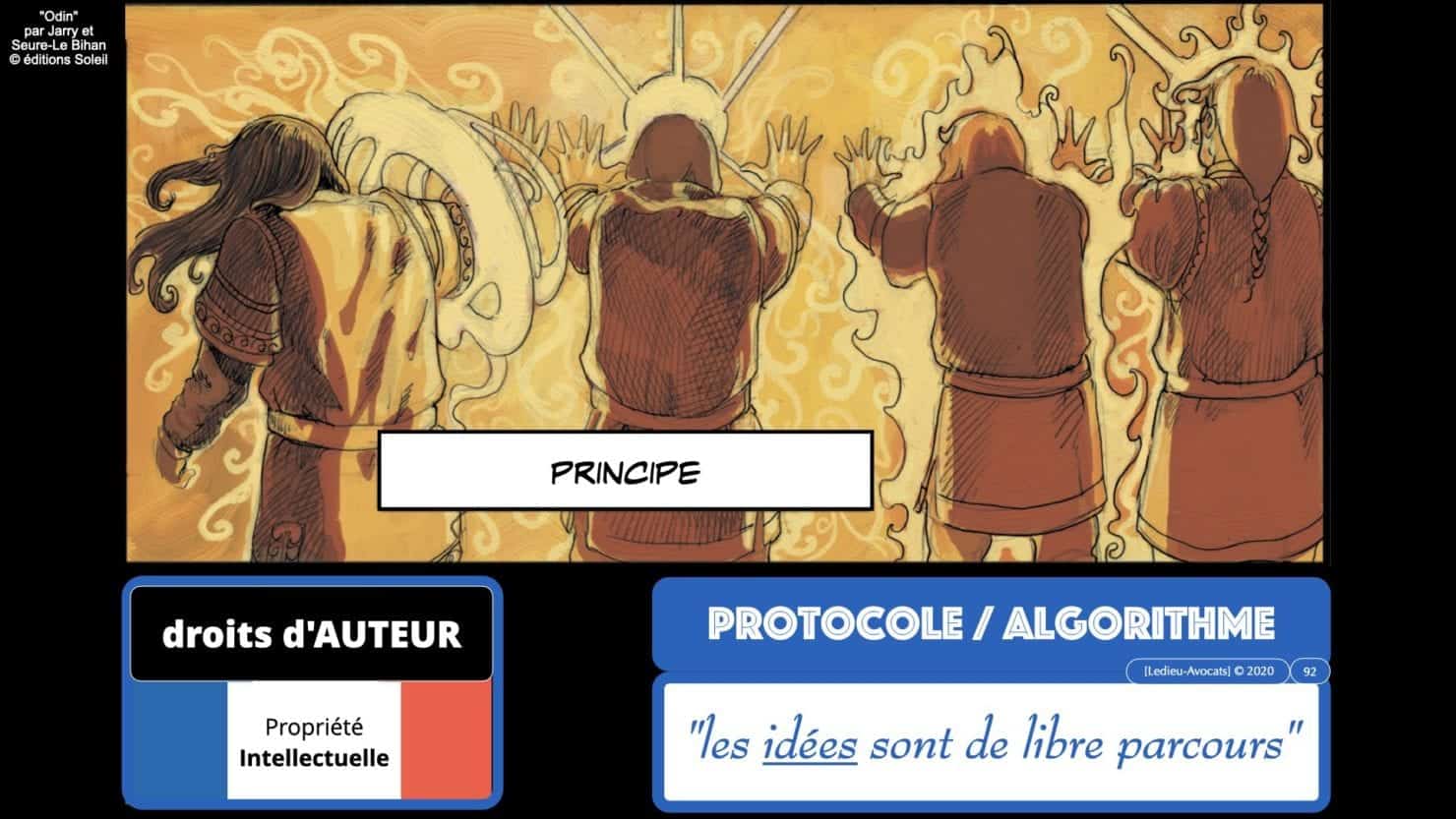
– le droit d’auteur (« les idées sont de libre parcours »…)
– le droit spécial du logiciel qui permet de protéger des codes source (s’ils sont « originaux » nous précise la jurisprudence française. C’est ici que nous inviterons à aller relire l’arrêt de la Cour d’Appel de Caen du 18 mars 2015 qui fait une juste distinction entre « logiciel » et « algorithme »
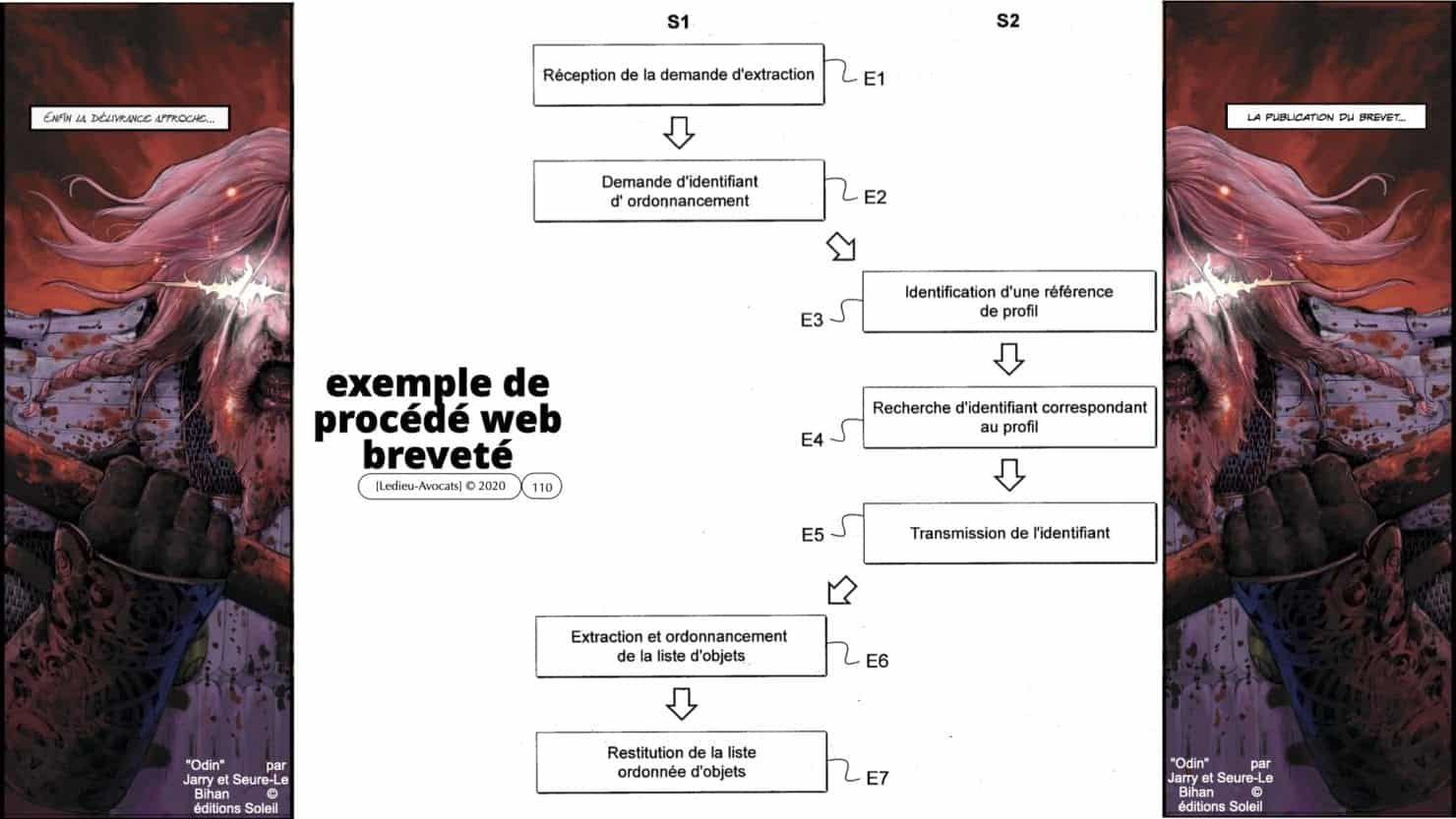
– nous évoquerons le droit du brevet car, dans une certaine mesure, un « algorithme d’intelligence artificielle / deep learning / machine learning » peut constituer une « invention » nouvelle « susceptible d’application industrielle ».
– nous terminerons avec la Directive sur les « secrets d’affaires », qui offre de loin la protection juridique la plus interessante.




























intelligence artificielle : découvrez les BD utilisées pour illustrer ces slides (et merci aux éditions Delcourt / Soleil !!!)









































![Ordre des Avocats de Paris PSSI et analyse des risques ISO 27001 [11 avril 2024]](https://technique-et-droit-du-numerique.fr/wp-content/uploads/2025/04/547-Ordre-des-Avocats-de-Paris-PSSI-et-analyse-des-risques-ISO-27001-11-avril-2024-©-Ledieu-Avocats-2024.001.jpeg)